
From Prompt Engineering to Context Engineering
by Nate Layman
What Shift Means for People Who Use AI But Don’t Build it
If you’ve spent any time using AI tools over the past couple of years, you’ve almost certainly engaged in “prompt engineering,” even if you are not yet familiar with the term. The concept is straightforward: the quality of what you get out of an AI depends heavily on how you ask. It’s a real skill, and people who develop it get noticeably better results.
However, in recent conversations around AI and its development a new term has emerged: context engineering. In mid-2025, the term gained traction rapidly after Shopify CEO Tobi Lütke and former OpenAI researcher Andrej Karpathy both endorsed it publicly.
Karpathy described it as “the delicate art and science of filling the context window with just the right information for the next step.”
Andrej Karpathy
Anthropic’s own engineering team published a detailed guide in September 2025 describing context engineering as the “natural progression” of prompt engineering.
So, what changed? And more importantly, why should someone in research administration, who uses AI tools but doesn’t build them, care about the distinction?
What Prompt Engineering Got Right
Prompt engineering is a real skill. When most people interacted with AI through a single chat box, typing one request and getting one response, the wording of that request genuinely mattered. A vague prompt got a vague answer. A well-structured prompt, with clear instructions, relevant constraints, and maybe an example of what you were looking for, got dramatically better results.
For research administrators, this produced practical gains almost immediately. Learning to write a good prompt meant you could get AI to draft a first pass of a facilities description, summarize a dense federal register notice, or reformat a budget justification to match a sponsor’s template. The skill was real, the results were tangible, and it remains valuable today.
But prompt engineering was always tied to the idea that your entire interaction with the AI happened in a single exchange. You typed something, the AI responded, and if the response wasn’t right, you tried again with different wording, iterating until you got an acceptable result. Prompt engineering was important largely because it was the only lever regular AI users had. However, recent developments enabled models to handle multi-step workflows, to preserve memory across conversations, to provide access to external documents and databases, to leverage tools like search engines, calculators, and code interpreters and many other new abilities. The AI you interact with today doesn’t just respond to your words. It draws from a much larger pool of information: your prior messages, documents you’ve uploaded, data it’s been given access to, instructions from the system that built it, and much more.
All that information, everything the AI can “see” when it generates a response, is called its context. And the maximum size of the context that a model can handle is called its context window. And it turns out that the quality of that context matters far more than the exact phrasing of any single prompt. As Karpathy put it, the shift is from asking smart questions to building smarter environments for the AI to work in.
This is what context engineering is: the practice of designing, curating, and managing the full set of information an AI has access to, not just the instruction you type, but the documents, memory, history, examples, and constraints that surround it. If prompt engineering is asking the right question in a meeting, context engineering is making sure everyone walks in having read the same briefing document first.
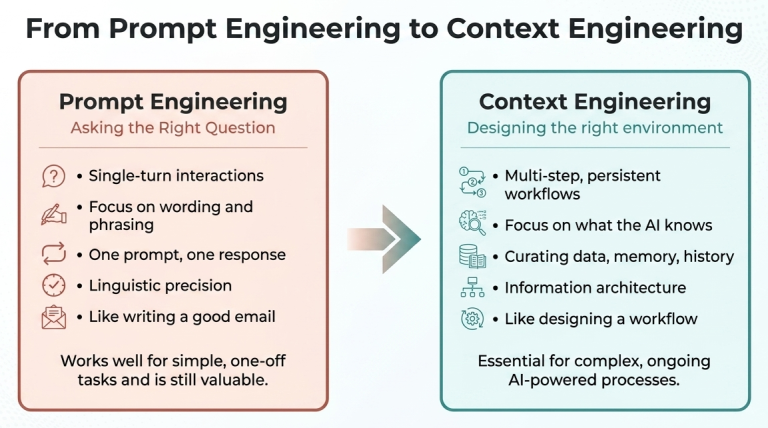
Is This Actually New?
The best prompt engineers have always stuffed relevant background information into their prompts. They provided examples (both positive and negative) of desired output formats and carefully structured their requests, generally in Markdown, to give the AI as much useful information as possible. But most people weren’t so meticulous, often leading to poor results. Now the “prompt” is just one small piece of a much larger information environment, and the stakes of getting things right have only grown. Context engineering is the practice of designing that environment deliberately, and it turns out that doing it well requires mastering not one skill but four.
Intent, Information, Instruction, and Interaction
Managing that information environment well requires four distinct skills: effectively communicating Intent, background Information, task Instruction, and dynamically Interacting with the model.
Together, these four skills determine success when utilizing AI tools. Further, because each priority competes for attention, effective AI use becomes less about mastering any one of them and more about balancing the different priorities well.
Why This Matters for Research Administration
Research administrators already think in terms of context, even if we don’t use those terms. When you set up a new grant specialist, you don’t just hand them a task and say “figure it out.” You give them the institutional policies, sponsor guidelines, the templates, historical examples, contact lists, and communicate the unwritten rules about how things work. You build the environment that makes them effective. Then the individual questions they ask are easy to answer, because the context is already in place.
Context engineering is the same idea applied to AI. Instead of asking “Can you draft a budget justification?” and hoping the AI guesses the right sponsor requirements, you design a system where the AI already has access to the funding opportunity announcement, your institution’s rate agreements, the PI’s prior budgets, and the relevant sections of the Uniform Guidance. The actual prompt becomes simpler because the hard work has already been done in setting up the context.
This all matters because prior to recent developments in AI tools, the most successful person who was the one best at talking to the machine. Now, context engineering rewards the person (or team, or institution) that is best at organizing information and designing processes. That’s a skill set research administrators already have in abundance.
What This Looks Like in Practice
You don’t need to be a developer to start thinking in terms of context engineering. Here are a few ways the concept shows up in everyday AI use for research administration:
Uploading documents before asking questions. When you upload a funding opportunity announcement and then ask the AI to summarize the eligibility
requirements, you’re doing context engineering. You’ve given the AI the source material it needs to drastically reduce the guesswork and likelihood of hallucinations.
Using custom instructions or system prompts. Many AI tools now let you set standing instructions: “I work at a public research university. Our F&A rate is 56%. We follow 2 CFR 200.” These persistent instructions mean you don’t have to repeat your institutional context every time you start a new conversation. That’s context engineering in its simplest form.
Building templates and workflows around AI. If your office creates a standard process where AI is given a specific set of documents, a defined output format, and a checklist of requirements every time it’s used for a particular task, you’ve engineered the context. Vandalizer was designed specifically to make AI workflows more effective, accurate, and re-usable. In this paradigm, the quality of the result depends less on who’s doing the prompting and more on how well the workflow was designed.
Curating what the AI doesn’t see. Context engineering isn’t just about adding more information. It’s also about knowing what to leave out. Overloading an AI with irrelevant documents can reduce its accuracy. Choosing the right three pages from a 200-page manual is itself an act of context engineering.
The Skill That’s Evolving
None of this means prompt engineering is dead. Knowing how to write a clear, well-structured request is still useful. But prompt engineering is just one part of context engineering. And it’s becoming evident that the higher-leverage skills are those that manage what happens before the prompt. Success depends on what information has been assembled, how it’s been organized, and whether the AI has what it needs to do its job well before the conversation even begins.
Fortunately, research administrators are skilled at organizing complex information, managing regulatory frameworks, and building processes that make other people’s jobs easier. For research administrators, context engineering should feel familiar. The work of research administration has always been about making sure the right information is in the right place at the right time, so that decisions can be made well. Context engineering is just that principle applied to one more tool in the toolkit.
How is context engineering different from a custom agent?
Thanks for the question! It’s a good one.
Let’s start with some definitions. The term “agent” has been growing in popularity recently but has taken on several meanings. My current definition is based on autonomy.
An agent is a system that can independently perform tasks and return a result without user input. It usually does this by making a plan, calling skills, and aggregating outputs.
Context, on the other hand, is background information that models needs in order to accomplish tasks. In fact it’s not necessary for an agent to be provided any context, as we’ve defined the term, in order to function. For example, an agent could consist of a set of skills that fetch and process data from a fixed, external source. In that case you wouldn’t need to provide any extra information when calling this kind of agent for it to be able to do it’s job.
However, agents are usually called by some kind of orchestrating interface, such as a chatbot. In that sense, the definition of the custom agents and the skills the orchestrator can use is, itself, a kind of context. It represents information that the chatbot needs in order to accomplish tasks.
So a custom agent definition can be provided as context, but context can also include things that have nothing to do with agents, such as a table of data or a website link.
Hopefully that makes sense! What are your thoughts?
Maybe we should write a post on agents and “agentic” AI?
Continuing on, and perhaps slightly nerdier, I view ‘context’ and ‘agent’ as orthogonal concepts. ‘Context’ is the information environment and an ‘agent’ is a unit capable of independent action. So context engineering is management of the information environment that things like agents use to perform tasks.
Hi Nathan, Thank you for the clarification, very helpful! I understand context engineering could be part of custom agent but can also be an independent framework for using any AI tool.