
Beyond Embeddings: Why Relationships Matter in RAG
By Nate Summers and Nate Layman
What is RAG and why is it useful?
RAG stands for Retrieval-Augmented Generation. It’s a technique designed to make LLMs better at finding relevant information (retrieval) and better at generating natural language responses (generation). This can be a very challenging task for anyone to do, let alone a semi-sentient pile of linear algebra. The main problem is that LLM’s have finite context windows and often suffer from a problem called context degradation. Essentially the more information you include in a query, the easier it is for a model to lose track of things. For large or complex tasks, the size of the context information necessary quickly grows to be too large and model performance rapidly breaks down (Du et al., 2025; Paulsen, 2025). Imagine asking an intern to read the entire library of congress and then be prepared to answer a random question on any topic.
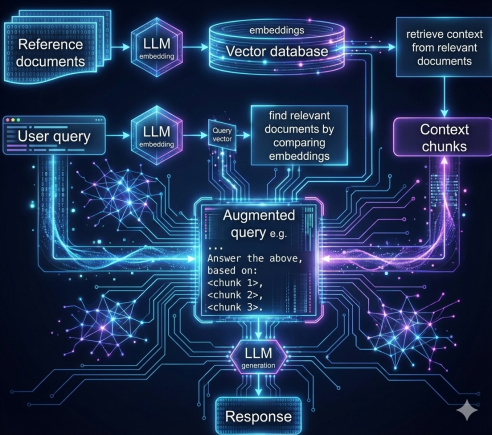
Instead, RAG techniques let models fetch only the pieces of information they actually need. For a human this might be using a catalog to identify the right book. RAG works by first chunking the data into bite sized pieces, known as indexing. Then it translates those chunks into numbers via a process called ‘embedding’ which get stored in a database. Finally, a RAG model navigates that database in order to fetch or retrieve relevant information. That way it can quickly and efficiently generate high quality, targeted, responses to user queries. There are a lot of nuances here — with different types of RAG such as graph rag, branched rag, and adaptive rag each building on those same basic steps (indexing, retrieval, generation) to solve different problems or add unique capabilities.
In research administration, traditional RAG can help by quickly retrieving relevant information from large databases or document collections. For example, it can help find funding opportunities that match a researcher’s interests, pull policy guidance from institutional and federal regulations, or locate past proposals and reports. By fetching only the most relevant pieces of information, RAG helps administrators generate targeted, useful answers without getting overwhelmed by the full set of documents.
However, while RAG is a powerful technique, a common challenge with most RAG methods is maintaining both relevance and coherence across chunked information. Even when the right chunks are pulled, the system can lose sight of the connective tissue between chunks. The relationships and dependencies between those fragments are often the parts that give meaning to the whole. In other words, traditional RAG approaches may be excellent at finding relevant pieces of information, but not necessarily at understanding how those pieces fit together. New ‘smart’ methods to overcome this challenge have recently started to emerge as a way to address this gap. One particularly interesting approach is Structured RAG.
Structured RAG
Structured RAG, presented by Guido van Rossum at PyBay 2025, directly addresses the “connective tissue” problem by fundamentally changing how we store and retrieve information. Rather than embedding raw text chunks into vectors, Structured RAG extracts and preserves the relationships between entities, creating a queryable knowledge graph.
How Structured RAG Works
Classic RAG embeds conversation turns into vectors and retrieves matches by cosine similarity. Structured RAG takes a different approach: extract structured knowledge first, then query it like a database.
Ingestion Phase:
- Run each conversation turn through an LLM to extract entities, relationships, actions, and topics
- Store these “knowledge nuggets” in a traditional database with inverted indices
- Preserve both extracted structure and pre-existing metadata (email headers, timestamps, locations)
Query Phase:
- Convert questions into database queries with scope expressions (time ranges, topics) and tree-pattern expressions (entity/relationship matches)
- Execute the query, rank by relevance
- Add top results to the answer prompt
This approach maintains the relationships between information fragments that traditional RAG often loses.
Claimed Advantages
The Microsoft team behind Structured RAG claims several advantages over classic RAG:
Information density - Storing structured knowledge nuggets rather than full message embeddings should be more space-efficient and allow for RAM-resident indices.
Query precision - Structured queries like “what email did Kevin send to Satya about new AI models?” should be more precise than cosine similarity searches. The structure prevents the model from returning “crimson t-shirts and blue soccer balls” when you ask about “the match where Messi used the crimson soccer ball.”
Inference capabilities - Type hierarchies enable query expansion (artist → person), helping with queries like “what people did we talk about yesterday?”
Hybrid knowledge - Combines extracted and pre-existing structure for richer queries, such as “what was the cactus I saw on my Arizona hike last month?”
In their demo, Structured RAG recalled all 63 books from 25 Behind the Tech podcasts with 3K tokens, versus 15 books for Classic RAG at 6K tokens (31 at 128K). Impressive if it holds up, though these are cherry-picked examples from a conference demo.
Trade-offs and Considerations
Ingestion is slower since it requires LLM calls for extraction rather than simple embedding generation. Query performance should be faster, though detailed benchmarks aren’t yet available.
The approach also adds architectural complexity; you’re building a knowledge-extraction pipeline and a query-translation layer on top of your conversation storage. For research administration use cases, this might be worthwhile for complex document collections where relationships between policies, regulations, and requirements are crucial.
Current Status
The core insight—that extracted, structured knowledge might perform better than raw embeddings—is compelling, especially in domains where relationships matter. Whether it delivers on the performance and precision claims at scale remains to be seen. The paper is still in progress and will be the real test.
The original TypeScript implementation comes from Steven Lucco and Umesh Madan at Microsoft (likely the forthcoming paper’s authors). Guido van Rossum handled the Python port and storage architecture, with much of the translation and refactoring work done by LLMs (usually Claude Sonnet).
The Python port (typeagent-py v0.3.2) is available now for experimentation. Just keep expectations calibrated until we see a more rigorous evaluation.
References
Du, X., Li, Y., Kumar, A., & Zhang, S. (2025). Context length alone hurts LLM performance despite perfect retrieval. arXiv. https://arxiv.org/abs/2510.05381
Paulsen, M. (2025). Context is what you need: The maximum effective context window for real-world limits of LLMs. arXiv. https://arxiv.org/abs/2509.21361